BLOG
Date:
Reading Time:
04 Minutes
Author
Himanshu Srivastava

What Is RAG (Retrieval-Augmented Generation)?
When RAG Is the Right Choice for Your Enterprise
When Fine-Tuning Is the Right Choice for Your Enterprise
The Hybrid Approach: Why Most Production Enterprise AI Uses Both
Common Enterprise Mistakes When Choosing Between RAG and Fine-Tuning
How Much Does Each Approach Cost?
Ready to Build Your Enterprise AI System the Right Way?
Frequently Asked Questions
Most enterprise AI projects fail not because of the model — but because of the wrong implementation strategy.
Choosing fine-tuning when RAG would have sufficed wastes months of compute time and budget. Choosing RAG for a task that requires embedded domain knowledge leads to inconsistent, unreliable outputs.
Getting this decision right early determines how fast you ship, how accurate your outputs are, and how much it costs to maintain the system over time.

What Is RAG (Retrieval-Augmented Generation)?
RAG is an architecture where the model retrieves relevant information from an external knowledge base at the time of inference and uses it to generate a response.
The model itself is not changed. Instead, it is given context — your documents, databases, or knowledge repositories — at the moment it answers a query.
How it works:
User asks a question
System searches your knowledge base for the most relevant content
Retrieved content is passed to the LLM as context
LLM generates a response grounded in your data
Best suited for:
Internal knowledge assistants and employee Q&A bots
Customer support systems that query product documentation
Legal and compliance tools that reference policy documents
Any use case where the underlying data changes frequently
Core advantage: No retraining required. Update your knowledge base and the model immediately reflects the change

What Is Custom LLM Fine-Tuning?
Fine-tuning is the process of taking a pre-trained foundation model — GPT-4, LLaMA, Mistral, or similar — and training it further on your proprietary dataset so it learns domain-specific language, behavior, and reasoning patterns.
The model's weights are updated. It does not retrieve information at inference time — it has internalized it.
How it works:
Prepare a high-quality, labeled dataset of domain-specific examples
Run supervised training on a foundation model using your dataset
The model updates its parameters to reflect your domain knowledge
Deploy the fine-tuned model for inference
Best suited for:
Medical, legal, or financial domains requiring precise terminology and reasoning
Products where the tone and response style must be consistent and brand-specific
Tasks like classification, extraction, or code generation in a niche domain
Applications where latency from retrieval is unacceptable
Core advantage: The model becomes deeply competent in your domain without needing external context at runtime.
RAG vs Fine-Tuning: Side-by-Side Comparison
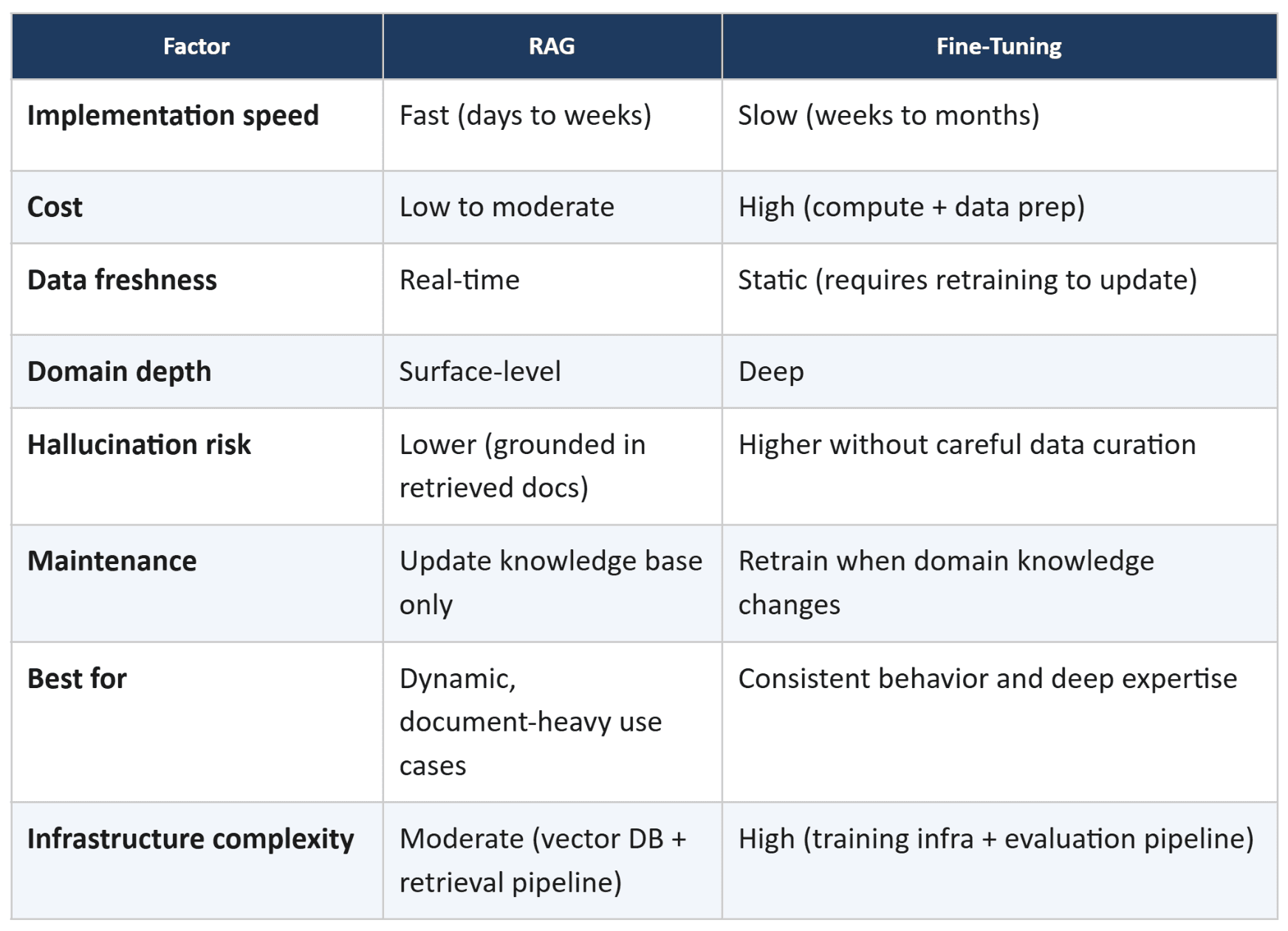

When RAG Is the Right Choice for Your Enterprise
RAG is the right starting point for most enterprise AI projects in 2026. It is faster to deploy, easier to maintain, and more transparent — you can trace every answer back to a source document.
Choose RAG when:
Your knowledge base updates weekly or monthly
You need source attribution for compliance or audit purposes
Your team does not have ML infrastructure for model training
You want to test an AI use case quickly before a larger investment
You are building an internal knowledge assistant, support bot, or document Q&A system
When Fine-Tuning Is the Right Choice for Your Enterprise
Fine-tuning is a significant investment — but the right one when the task requires more than retrieval can offer.
Choose Fine-Tuning when:
Your domain has specialized vocabulary the base model does not understand well
You need the model to generate structured outputs consistently (medical reports, legal summaries, code)
Response latency is critical and retrieval overhead is not acceptable
You need the model to follow a specific reasoning pattern or decision framework
You are building a product — not an internal tool — where quality and reliability are non-negotiable
The Hybrid Approach: Why Most Production Enterprise AI Uses Both
In practice, the most robust enterprise AI systems in 2026 combine fine-tuning and RAG in a layered architecture.
How it works:
Fine-tune the base model on your domain so it understands your language, terminology, and reasoning style
Layer RAG on top so it retrieves current, specific information at inference time
The result is a model that speaks your domain fluently and answers accurately from live data
Example: A financial services firm fine-tunes a model on regulatory documents to embed compliance reasoning, then uses RAG to retrieve the latest policy updates at query time. Neither approach alone would deliver the same accuracy.
This hybrid model is more expensive to build but delivers production-grade reliability that single-approach systems cannot match.
Common Enterprise Mistakes When Choosing Between RAG and Fine-Tuning
Jumping to fine-tuning too early is the most expensive mistake. Most use cases can be solved with RAG first — reserve fine-tuning for when retrieval consistently fails to meet quality requirements.
Treating RAG as a search engine misses its potential. RAG is not just document search — when designed well, it reasons across multiple retrieved sources to produce synthesized, accurate answers.
Neglecting data quality for fine-tuning is a critical error. A fine-tuned model is only as good as the training data. Poor labeling, inconsistent examples, and insufficient volume all produce unreliable models.
Ignoring evaluation frameworks before deployment leads to blind spots. Both RAG pipelines and fine-tuned models need rigorous evaluation — precision, recall, hallucination rate, and task-specific benchmarks.
How Much Does Each Approach Cost?
RAG implementation cost for an enterprise system typically depends on the size of the knowledge base, retrieval complexity, and integration requirements.
Fine-tuning cost varies significantly — for a focused task on a smaller model to a large foundation model fine-tuned on a proprietary enterprise dataset.
Ongoing maintenance for RAG is lower — primarily knowledge base management. Fine-tuned models require periodic retraining as domain knowledge evolves
Ready to Build Your Enterprise AI System the Right Way?
Choosing between Fine-Tuning and RAG is not just a technical decision — it is a strategic one. The wrong choice costs months of development time and a significant budget.
NeuraDynamics has helped enterprises across Healthtech, Fintech, EdTech, and eCommerce design and deploy production-grade AI systems — from RAG-powered knowledge assistants to fine-tuned domain models built for scale.
Frequently Asked Questions
Can RAG replace fine-tuning entirely?
For most enterprise use cases — yes. RAG handles the majority of document-grounded Q&A, support, and knowledge retrieval tasks without the cost and complexity of fine-tuning. Fine-tuning remains essential for deep domain specialization and consistent structured output generation.
How long does it take to implement a RAG system?
A focused RAG deployment for an enterprise knowledge base typically takes 3–6 weeks, including document ingestion, vector database setup, retrieval pipeline configuration, and evaluation.
How long does fine-tuning an LLM take for an enterprise use case?
A fine-tuning project typically takes 8–16 weeks — covering dataset preparation, training runs, evaluation cycles, and deployment. Timeline varies by model size and dataset complexity.
What is the biggest risk of fine-tuning?
Overfitting on low-quality or insufficient training data — which produces a model that performs well on training examples but fails on real-world inputs. Data quality is the single most important variable.
Do we need an in-house ML team to implement RAG or fine-tuning?
Not necessarily. A specialist AI development partner can design, build, and deploy both architectures. For ongoing maintenance, a smaller in-house team or on-demand AI support model is typically sufficient.
Author

Himanshu is the Founder of Neuradynamics and a seasoned Full Stack Developer with 15+ years of experience in application development, cloud infrastructure, automation, and scalable digital solutions. With expertise across Python, Django, AWS, Azure, and AI-powered systems, he shares practical insights on modern technology, software architecture, and digital transformation.
